
Re:제로부터 시작하는 갓생
[ML] 본문
1. 머신러닝의 기본 개념과 활용 사례
개요:
- 머신러닝이란?
- 정의와 기본 원리 소개
- 데이터 기반의 학습 및 예측
- 머신러닝의 주요 알고리즘
- 감독학습 (Supervised Learning)
- 분류 (Classification)
- 회귀 (Regression)
- 비지도학습 (Unsupervised Learning)
- 군집 (Clustering)
- 강화 학습 (Reinforcement Learning)
- 감독학습 (Supervised Learning)
- 실제 활용 사례
- 일상생활에서의 활용 사례
- 산업별 활용 사례 (의료, 금융, 교통 등)
금융: 신용평가, 주식예측
헬스케어: 질병예측, 환자데이터분석
이커머스: 장바구니분석, 고객 구매 패턴 분석, 가격 최적화
- 미래 전망
- 머신러닝의 발전 방향
- 윤리적 문제와 도전 과제
상세 내용:
서론
- 머신러닝의 중요성: 오늘날의 기술 발전과 데이터의 폭발적인 증가로 인해 머신러닝이 중요한 역할을 함
- 블로그 글을 쓰게 된 이유: 공부를 하며 내용을 정리하고 얻게되는 인사이트 공유
본론
1. 머신러닝이란?

- 정의: 머신러닝은 컴퓨터가 명시적 프로그래밍 없이도 학습하고 예측할 수 있도록 하는 기술.
- Machine Learning 대용량 데이터 패턴을 인식, 예측, 분류하는 방법론
- 데이터 수집, 전처리, 모델 학습, 평가 및 예측의 순환 과정 설명.
- 기본원리: 데이터 기반으로 패턴을 인식하고 예측 모델을 구축하는 과정
- 예시: 많은 이미지 데이터를 통해 고양이인지 강아지인지 예측하는 것
2. 머신러닝의 주요 알고리즘
- 감독학습 (Supervised Learning):
- 정의: 입력 데이터와 그에 상응하는 정답이 주어진 상태에서 모델을 학습.
- 분류 (Classification): 범주를 맞추는 방법. 데이터를 여러 범주로 나누는 방법
- 예시: 이메일 스팸 필터링, 이미지 인식.
- 장단점: 높은 정확도와 예측 가능성, 다만 많은 레이블 데이터가 필요.
- 회귀 (Regression): 숫자를 맞추는 방법. 연속적인 값을 예측하는 방법
- 예시: 주택 가격 예측, 주식 시장 예측.
- 장단점: 정확한 값 예측 가능, 다만 과적합(overfitting) 문제 발생 가능.
* 회귀 분류
1) 선형 회귀 (Linear Regression):
# 통계학에서 사용하는 선형회귀 식
𝑦 = 𝛽₀ + 𝛽₁Ⅹ+ 𝜀
Y = \beta_0 + \beta_1X + \varepsilon
𝛽₀: 편향(Bias), 절편
𝛽₁: 회귀 계수, 기울기
𝜀: 오차(에러), 모델이 설명하지 못하는 Y의 변동성
# 머신러닝/딥러닝에서 사용하는 선형회귀 식
𝑦 = 𝑤Ⅹ + b
Y = wX + b
𝑤: 가중치, 추정치
b: 편향(Bias), 통계학식에서의 𝛽+𝜀- 정의: 독립 변수와 종속 변수 간의 정량적인 차이에 대해 관심을 가지고 선형 관계를 모델링하는 기법. 데이터를 보고 두 변수 사이의 관계 찾는 것
- 예시: 광고 비용과 매출 간의 관계 예측. 공부시간과 점수 사이의 관계 찾기
- 장단점: 단순하고 해석하기 쉬운 모델, 다만 비선형 관계를 처리하기 어렵다.
2) 회귀분석 평가지표 (Evaluation Metrics for Regression Analysis):
- 평가지표: 모델의 성능을 평가하기 위한 지표. 모델이 얼마나 잘 맞추는지 평가하는 방법
- MSE(평균 제곱 오차), RMSE(평균 제곱근 오차), R²(결정 계수) 등을 포함
# Mean Squared Erorr 정의
MSE = \frac{\sum\limits_{i=1}^n (y_i - \hat{y_i})^2}{n}
# RMSE: MSE에 Root를 씌워 제곱된 단위를 다시 맞추기
RMSE = \sqrt{\frac{\sum\limits_{i=1}^n (y_i - \hat{y_i})^2}{n}}
# MAE: 절대값을 이용해 오차 계산
MAE = \frac{1}{n}\sum\limits_{i=1}^n{\left\vert y_i - \hat{y_i} \right\vert}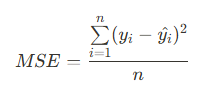


- 예시: 주택 가격 예측에서 모델의 정확도 평가. 모델이 예측한 점수와 실제 점수 차이 확인
- 장단점: 다양한 지표를 통해 모델의 성능을 다각도로 평가할 수 있음.
- ^ : 추정치를 의미
2-2) 선형회귀만의 평가지표 (R Square)

-
- yi: 특정 데이터의 실제 값
- Ῡ: 평균 값
- ŷ: 예측, 추정한 값
- SST(Sum of Squre Total)
- SSR(Sum of Squre Regression): 높으면 높을수록 좋음
- SSE(Sum of Squre Error): 낮으면 낮을수록 좋음
3) 로지스틱 회귀 (Logistic Regression) - 타이타닉 생존 분류 문제:
- 정의: 이진 분류 문제를 해결하기 위한 회귀 기법. 두 가지 선택지 중 하나를 고르는 문제를 푸는 것
- 예시: 타이타닉 탑승자의 생존 여부 예측. 누가 살아남을지 예측
- 장단점: 해석하기 쉽고, 확률을 출력하지만, 데이터가 선형적으로 분리되지 않으면 성능이 떨어질 수 있음.
4) 로지스틱 회귀 이론 및 실습:
- 이론: 로지스틱 함수와 로지스틱 회귀의 기본 원리 설명. 확률을 계산하는 방식
- 실습: 파이썬을 사용한 실제 데이터셋으로 로지스틱 회귀 모델 훈련 및 평가. 컴퓨터 프로그램을 사용해 실제 데이터 분석
- 장단점: 이론적인 배경과 실제 적용을 통해 이해를 돕는다.
5) 다중 로지스틱 회귀 (Multinomial Logistic Regression):
- 정의: 다중 클래스 분류 문제를 해결하기 위한 로지스틱 회귀 기법. 여러 선택지 중 하나를 고르는 문제 푸는 것
- 예시: 다양한 과일 이미지 분류. 과일사진을 보고 사과, 바나, 포도 중에 무엇인지 맞힘
- 장단점: 여러 클래스를 동시에 분류할 수 있지만, 모델의 복잡성이 증가할 수 있음
- 비지도학습 (Unsupervised Learning):
- 정의: 정답 레이블 없이 입력 데이터의 패턴을 학습. 정답이 없는 문제를 푸는 것. 컴퓨터가 스스로 패턴 찾아냄
- 군집 (Clustering): 비슷한 것끼리 묶는 것
- 예시: 고객 세분화, 이미지 압축. 비슷한 취향의 친구들을 그룹으로 나누기
- 장단점: 데이터 레이블이 필요 없지만, 결과 해석이 어려울 수 있음.
- 강화 학습 (Reinforcement Learning):
- 정의: 에이전트가 환경과 상호작용하며 최적의 행동을 학습. 상과 벌을 통해 학습
- 예시: 게임 AI, 로봇 제어. 게임에서 점수를 얻기 위해 더 잘하려고 노력함. 캐릭터가 장애물을 피하며 점수 얻기
- 장단점: 실제 환경에서 학습 가능, 학습 속도가 느릴 수 있음
*
3. 실제 활용 사례
- 일상생활에서의 활용: (딥러닝의 사례)
- 추천 시스템: 넷플릭스나 유튜브의 맞춤형 추천
- 음성 인식: 스마트폰 음성 비서
- 자연어처리: 번역, 챗봇, 텍스트 분석
이미지&영상처리: 얼굴인식, 이미지 생성
- 산업별 활용 사례:
- 의료: 질병 진단, 약물 개발
- 금융: 신용 평가, 사기 탐지
- 교통: 자율 주행 자동차, 교통 흐름 최적화
4. 미래 전망
- 머신러닝의 발전 방향:
- 지속적인 알고리즘 개선과 데이터 처리 기술의 발전
- 더 많은 산업과 일상생활에의 확장 가능성
- 윤리적 문제와 도전 과제:
- 프라이버시 문제, 데이터 편향성, 인공지능의 투명성과 설명 가능성
결론
- 머신러닝의 현재와 미래:
- 현재의 발전 상황을 요약하고, 앞으로의 기술적 도전과 가능성에 대해 전망
- 머신러닝이 가져올 변화와 기회
참고자료
머신러닝의 이해와 라이브러리 활용 기초 (임정 튜터)
'Tech Stack > Docs' 카테고리의 다른 글
| [Tableau] (0) | 2025.02.12 |
|---|---|
| [Pandas] (0) | 2025.01.14 |
| [Python] (0) | 2025.01.14 |
| [SQL] (0) | 2025.01.12 |
| [Statistics] (0) | 2025.01.09 |
'Tech Stack/Docs' Related Articles
more

